Según el reporte de contingencias de la Autoridad Nacional de Licencias Ambientales (ANLA) de Colombia, se registraron 13630 incidentes ambientales de 1990 a 2025, provocados por empresas del sector petrolero, minero y químico. Este resultado enmarca un campo de análisis y acción en favor del cuidado del medio ambiente.
Como parte de un proyecto de investigación para la Maestría de Estadística Aplicada y Ciencia de Datos de la Universidad El Bosque, los investigadores Daniel Navarrete y Milena Ávila han desarrollado un sistema de inteligencia artificial que busca predecir incidentes ambientales en los departamentos y municipios en los que existen operaciones industriales registradas debidamente por la ANLA.
Este sistema se encuentra en una versión demo y su fin es establecer un primer hito en el incansable proceso científico de encontrar un modelo que explique la ocurrencia de dichos fenómenos.
Le invitamos a probar la aplicación y, si así lo desea, puede revisar una reseña que describe los hitos más importantes del proceso de entrenamiento e ingeniería de datos debajo de la aplicación.
¡Prueba la app! Experimenta los valores de entrada y dale al botón 🚀 PREDECIR. Desplaza la barra para ver el resultado en el MAPA
El modelo y su proceso de entrenamiento
Este fue un proyecto retador. Lograr predecir tipos de evento, lugares y número de veces de ocurrencia de accidentes ambientales significó una exploración profunda del problema y de modelos que fueran capaces de reflejar estos fenómenos. Pero el conjunto de datos empleado para la construcción de estos modelos es vasto: 13630 observaciones (filas) y 91 variables originales, suponen un poder potencial informativo que podría ser aprovechado para modelar eventos futuros a fin de establecer estrategias de prevención y/o mitigación oportunas.
La presente descripción no intenta ser técnicamente exhaustiva, sino más bien buscará proveer al lector un panorama general del proceso y resultados de lo desarrollado.
El dataset
El conjunto de datos empleado para el entrenamiento de los modelos es de acceso abierto y se encuentra bajo responsabilidad de la Autoridad Nacional de Licencias Ambientales (ANLA). Estos datos surgen del registro que la ANLA realiza, a partir de los reportes que presentan las empresas que operan en el sector petrolero, minero y químico. Las dimensiones del conjunto de datos son de 13630 registros y 91 variables relacionadas a localización geográfica, características del evento, sustancias involucradas, afectación ambiental, entre otras.
Como corresponde, se realizó una exploración inicial de los datos con el fin de entender la naturaleza de estos y sus características, como formatos, distribuciones, relaciones e influencias. Este análisis ayudó también a comprender cómo abordar el entrenamiento de los modelos.
Los modelos de machine learning empleados
Luego de un proceso complejo de preprocesamiento e ingeniería de variables (definir y transformar las variables idóneas para el entrenamiento) se procedió a busca el modelo ideal. Es importante recordar que el desafío del proyecto reside en modelizar un fenómeno con tres variables de interés: ubicación geográfica del accidente, tipo de accidente y número de veces que puede ocurrir el accidente en el día y mes seleccionado.
Problema 1: Predecir las coordenadas en donde pueden ocurrir los accidentes ambientales
Este fue el problema más difícil. El reto fue encontrar un modelo de regresión que estime tanto la latitud y longitud con un RMSE (error cuadrático medio) lo más pequeño posible. Los experimentos iniciales arrojaban un RMSE de 1.2 – 1.5, lo cual representa un resultado muy alto. Para que hacerse una idea: cada grado equivale en promedio a 111 km., lo que quiere decir que los primeros ensayos predecían con un error de más de 160 kilómetros para latitud y longitud cada uno. Tener un modelo con tan poco poder predictivo no tiene utilidad alguna.
Fue por eso que se continuó con la exploración y experimentación de diversos modelos y estrategias. Una de ellas fue cambiar el alcance de la predicción y esto fue lo que determinó el éxito de esta primera versión. Los modelos iniciales intentaban hacer una regresión por cada punto en el plano territorial de Colombia, lo cual carece de sentido, ya que no existen operaciones, oleoductos y otras intervenciones en todos los departamentos del territorio nacional. La actividad productiva de esos sectores solamente están presentes en algunos departamentos del país. Es así que se redujo el alcance mediante la definición de aquellos municipios en donde se registró una actividad y se volvió al proceso de experimentación. La capacidad de generalización no debería ser una preocupación, ya que, como se señaló anteriormente, no tiene sentido estimar cualquier latitud y longitud en donde puede ocurrir un accidente en Colombia. Por ejemplo, de qué sirve esperar que el modelo prediga que en el centro de Bogotá habrá un accidente ambiental por derrame químico si ahí no existen actividades industriales categorizados por la ANLA. Es importante mencionar, además, que el proceso de entrenamiento incluyó la aplicación de validación cruzada estratificada de tipo shuffle que ayuda a evitar la fuga de datos entre los conjuntos de entrenamiento-validación y test.
RESULTADOS:
Inicialmente, se entrenó un autoencoder que reduce a la mínima expresión significativa de los datos y luego con un proceso de clustering se encuentran grupos que comparten patrones. Esto ayudó a identificar mejor zonas de incidencias. A partir de ahí, se probaron regresores de Random Forest, redes neuronales, modelos stacking y el que mejor tuvo resultado (no sorprende) fue XGBoost. La configuración 2 de hiperparámetros estuvo orientada a reducir el RMSE con árboles más profundos y mayor regularización, 800 estimadores, una tasa de aprendizaje más baja y penalizaciones L1 y L2. El resultado fue el siguiente:
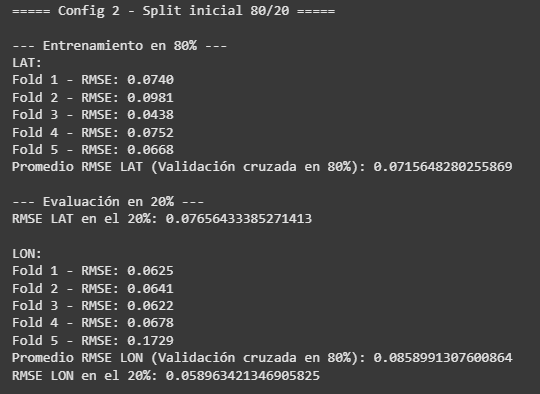
Como se puede observar, el RMSE para la variable latitud bajó a 0.07 y para longitud 0.05 sobre el conjunto de test (datos que no vio el modelo). Esto representa una mejora considerable de la efectividad del modelo porque para longitud, por ejemplo, el error es sol ode 5.55 km. (los primeros ensayos arrojaban 166 kilómetros de error).
Para lograr mayor interpretabilidad del resultado, se aplicó la fórmula Harvesine que ayuda a transformar el RMSE en un formato espacial real:
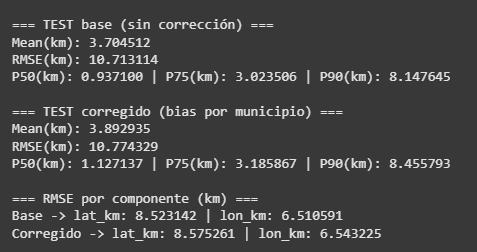
Se puede observar que en el conjunto de test, el modelo logró un RMSE en kilómetros de 10.77 km. (frente a los 235 kilómetros iniciales).
Problema 2: Predecir los tipos de evento
El reporte de contingencias posee una amplia variedad de tipos de eventos. Muchos de ellos tienen poca frecuencia, casi insignificante. Otros, por el contrario, dominan los registros, como es el caso de los derrames de sustancias químicas en estado sólido y líquido. Esto hace que el problema se vuela complejo porque nos encontramos frente a un problema de desbalance de clases (¿cómo logramos que el modelo aprenda los patrones detrás de una clase que tiene poca frecuencia?). Para enfrentar este desafío, se agrupó en la clase ‘OTRO’ todas las clases que tenían muy poca frecuencia. Admás, se apostó por aplicar SMOTE como técnica de muestreo en cada uno de los folds durante el proceso de validación cruzada estratificada, a fin de generar instancias sintéticas de las cuales el modelo pueda aprender. Al final la variable TIPO DE EVENTO quedó con seis clases, de las cuales cinco eran originales y una sintética (OTRO).
RESULTADOS:
El mejor modelo para este caso fue también XGBoost, pero esta vez un clasificador. La configuración de hiperparámetros tuvo el objetivo de encontrar un equilibrio entre regularización y capacidad, los árboles no eran profundos, pero sí muchos (500 estimadores), con una tasa de aprendizaje pequeña y muestreo parcial para evitar el sobreajuste. El resultado fue el siguiente:
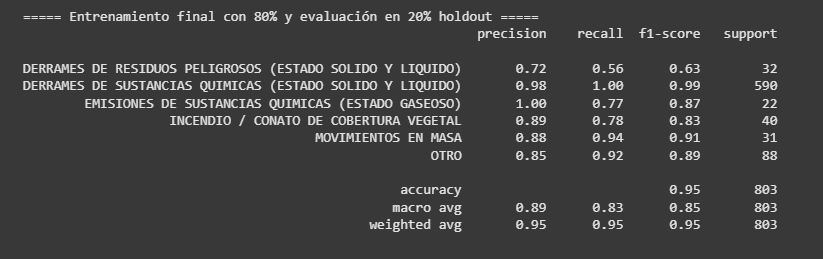
Las métricas mejoraron mucho para cada clase. El indicador precision indica que todos los que el modelo dijo que eran de esa clase realmente lo eran. Por ejemplo, el 0.72 en DERRAMES DE RESIDUOS PELIGROSOS indica que el modelo acertó 7 veces cuando dijo que eran 10 los eventos de esa clase. Por otro lado, recall muestra la tasa de efectividad del modelo para encontrar todos los eventos existentes de esa clase (verdaderos positivos). Siguiendo el ejemplo anterior, el modelo de 10 eventos de movimientos de masa que existen, encontró 9.
El resultado de 1.00 en algunas clases / métricas significa que el modelo es perfecto. No existe un modelo perfecto, por esa razón, aunque no quiere decir que el modelo esté ‘mintiendo’ en que es efectivo, sí puede estar exagerando. Pruebas adicionales son necesarias para reflejar mejor el comportamiento real del modelo para esas clases y métricas.
Problema 3: Predecir el número de veces que ocurre determinado evento
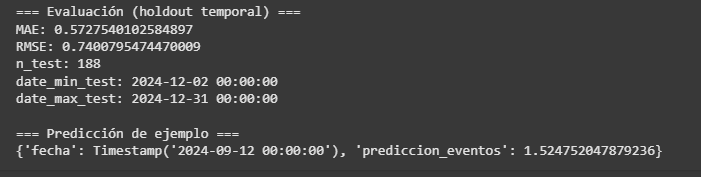
FInalmente, el modelo para estimar el número de veces de cierto tipo de accidente, fue el último y más sencillo de implementar (frente a los otros). Se empleó un modelo de regresión Poisson con max_iter=1000 para aprender la mejor solución y un alpha=0.5 para aplicar una penalización moderada y así evitar el sobreajuste.
RESULTADOS:
Los resultados indican que el modelo es conservador en sus estimaciones, con un RMSE del 0.72. Esto indica que el modelo no es del todo confiable y debemos ser cuidadosos con las estimaciones que haga.
Utilidad del sistema
Este sistema puede ayudar a anticipar la carga de incidentes ambientales en cada municipio, sector y subsector para fechas específicas. Esto ayuda a que las autoridades ambientales o las empresas planeen recursos (personal, equipos, transporte) con base en una estimación objetiva del número esperado de eventos.
Pronto se enriquecerá esta sección para entender las implicancias y potencial aprovechamiento de este sistema.